Python에서 얕은 목록 평탄화
목록 이해로 반복 가능한 목록을 정리할 수 있는 간단한 방법이 있습니까? 그렇지 않으면 성능 및 가독성을 균형 있게 유지하면서 이렇게 얕은 목록을 정리할 수 있는 가장 좋은 방법은 무엇이라고 생각하십니까?
나는 네스트된 목록 이해로 이러한 목록을 평평하게 만들려고 했다.
[image for image in menuitem for menuitem in list_of_menuitems]
그 때문에 요.NameErrorname 'menuitem' is not defined. Overflow를 . Stack Overflow로 reduce★★★★★★★★
reduce(list.__add__, map(lambda x: list(x), list_of_menuitems))
이 은 제가 그 방법이 수 .list(x) x이기 한다.QuerySet★★★★★★ 。
결론:
이 질문에 참여해 주신 모든 분들께 감사드립니다.여기 내가 배운 것의 요약이 있다.또한 다른 사람이 이러한 관찰을 추가하거나 수정하고자 할 경우에 대비하여 커뮤니티 위키로 만듭니다.
원래 축소 문장은 중복되어 있으며 다음과 같이 작성되어 있습니다.
>>> reduce(list.__add__, (list(mi) for mi in list_of_menuitems))
이는 중첩된 목록 이해(Brilliant summary dF!)에 대한 올바른 구문입니다.
>>> [image for mi in list_of_menuitems for image in mi]
이 두 방법 모두 이지는 않습니다.itertools.chain:
>>> from itertools import chain
>>> list(chain(*list_of_menuitems))
@ 노트처럼 @cdleary * @cdleary * @cdleary magic을 도 모릅니다.chain.from_iterable다음과 같이 합니다.
>>> chain = itertools.chain.from_iterable([[1,2],[3],[5,89],[],[6]])
>>> print(list(chain))
>>> [1, 2, 3, 5, 89, 6]
데이터 구조의 평탄한 버전을 반복하고 인덱스 가능한 시퀀스가 필요하지 않은 경우 itertools.chain 및 company를 고려해 보십시오.
>>> list_of_menuitems = [['image00', 'image01'], ['image10'], []]
>>> import itertools
>>> chain = itertools.chain(*list_of_menuitems)
>>> print(list(chain))
['image00', 'image01', 'image10']
수 있는 것이며, 장고의 할 수 있는 것을 포함해야 .QuerySets: 문문 s s s s s s s s s s s s s s s s.
편집: reduce는 확장 중인 목록에 항목을 복사하는 것과 동일한 오버헤드가 발생하므로 이 방법은 reduce와 같은 효과를 얻을 수 있습니다. chain이 () 오버헤드가 합니다.이 오버헤드가 발생하는 것은, 「」(동일)을 뿐입니다.list(chain)마지막에.
메타 편집:원래 임시 목록을 임시로 확장할 때 작성한 임시 목록을 버리기 때문에 질문에서 제안한 솔루션보다 오버헤드가 적습니다.
편집: J.F.로. 세바스찬은 말한다 itertools.chain.from_iterable을 피해야 .*매직하지만 타임잇 앱은 거의 성능 차이를 보이지 않습니다.
거의 다 됐어!네스트 리스트 컴플리먼트를 실행하는 방법은,for과 같은 를 설정합니다.for★★★★★★★★★★★★★★★★★★.
이렇게 해서
for inner_list in outer_list:
for item in inner_list:
...
대응하다
[... for inner_list in outer_list for item in inner_list]
그래서 네가 원하는 건
[image for menuitem in list_of_menuitems for image in menuitem]
@S.Lott: 당신이 나에게 타임릿 앱을 만들도록 영감을 주었습니다.
파티션 수(컨테이너 리스트 내의 반복자 수)에 따라서도 다르다고 생각했습니다만, 코멘트에서는 30개의 아이템 중 몇 개의 파티션이 있었는지에 대해서는 언급하지 않았습니다.이 그래프는 각 런에서 파티션의 수를 다르게 하여 1,000개의 항목을 평탄화합니다.항목은 파티션 간에 균등하게 분배됩니다.
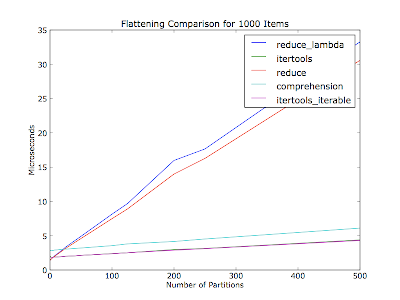
코드(Python 2.6):
#!/usr/bin/env python2.6
"""Usage: %prog item_count"""
from __future__ import print_function
import collections
import itertools
import operator
from timeit import Timer
import sys
import matplotlib.pyplot as pyplot
def itertools_flatten(iter_lst):
return list(itertools.chain(*iter_lst))
def itertools_iterable_flatten(iter_iter):
return list(itertools.chain.from_iterable(iter_iter))
def reduce_flatten(iter_lst):
return reduce(operator.add, map(list, iter_lst))
def reduce_lambda_flatten(iter_lst):
return reduce(operator.add, map(lambda x: list(x), [i for i in iter_lst]))
def comprehension_flatten(iter_lst):
return list(item for iter_ in iter_lst for item in iter_)
METHODS = ['itertools', 'itertools_iterable', 'reduce', 'reduce_lambda',
'comprehension']
def _time_test_assert(iter_lst):
"""Make sure all methods produce an equivalent value.
:raise AssertionError: On any non-equivalent value."""
callables = (globals()[method + '_flatten'] for method in METHODS)
results = [callable(iter_lst) for callable in callables]
if not all(result == results[0] for result in results[1:]):
raise AssertionError
def time_test(partition_count, item_count_per_partition, test_count=10000):
"""Run flatten methods on a list of :param:`partition_count` iterables.
Normalize results over :param:`test_count` runs.
:return: Mapping from method to (normalized) microseconds per pass.
"""
iter_lst = [[dict()] * item_count_per_partition] * partition_count
print('Partition count: ', partition_count)
print('Items per partition:', item_count_per_partition)
_time_test_assert(iter_lst)
test_str = 'flatten(%r)' % iter_lst
result_by_method = {}
for method in METHODS:
setup_str = 'from test import %s_flatten as flatten' % method
t = Timer(test_str, setup_str)
per_pass = test_count * t.timeit(number=test_count) / test_count
print('%20s: %.2f usec/pass' % (method, per_pass))
result_by_method[method] = per_pass
return result_by_method
if __name__ == '__main__':
if len(sys.argv) != 2:
raise ValueError('Need a number of items to flatten')
item_count = int(sys.argv[1])
partition_counts = []
pass_times_by_method = collections.defaultdict(list)
for partition_count in xrange(1, item_count):
if item_count % partition_count != 0:
continue
items_per_partition = item_count / partition_count
result_by_method = time_test(partition_count, items_per_partition)
partition_counts.append(partition_count)
for method, result in result_by_method.iteritems():
pass_times_by_method[method].append(result)
for method, pass_times in pass_times_by_method.iteritems():
pyplot.plot(partition_counts, pass_times, label=method)
pyplot.legend()
pyplot.title('Flattening Comparison for %d Items' % item_count)
pyplot.xlabel('Number of Partitions')
pyplot.ylabel('Microseconds')
pyplot.show()
편집: 커뮤니티 Wiki로 결정.
METHODS아마 데코레이터로 쌓아야 할 것 같은데 이런 식으로 읽는 게 더 쉬울 것 같아요.
sum(list_of_lists, [])이치노
l = [['image00', 'image01'], ['image10'], []]
print sum(l,[]) # prints ['image00', 'image01', 'image10']
이 솔루션은 다른 솔루션의 일부(전체)가 제한된 "목록" 깊이뿐만 아니라 임의 중첩 깊이에도 작동합니다.
def flatten(x):
result = []
for el in x:
if hasattr(el, "__iter__") and not isinstance(el, basestring):
result.extend(flatten(el))
else:
result.append(el)
return result
임의 깊이 중첩이 가능한 재귀입니다. 물론 최대 재귀 깊이에 도달할 때까지...
Python 2.6에서는 다음을 사용합니다.
>>> from itertools import chain
>>> list(chain.from_iterable(mi.image_set.all() for mi in h.get_image_menu()))
중간 목록을 만들지 않습니다.
퍼포먼스 결과개정.
import itertools
def itertools_flatten( aList ):
return list( itertools.chain(*aList) )
from operator import add
def reduce_flatten1( aList ):
return reduce(add, map(lambda x: list(x), [mi for mi in aList]))
def reduce_flatten2( aList ):
return reduce(list.__add__, map(list, aList))
def comprehension_flatten( aList ):
return list(y for x in aList for y in x)
30개 항목의 2단계 목록을 1000번 평활화했다.
itertools_flatten 0.00554
comprehension_flatten 0.00815
reduce_flatten2 0.01103
reduce_flatten1 0.01404
줄이는 것은 항상 좋지 않은 선택이다.
와와 there there there there에 혼동이 있는 것 .operator.add! 함께 , 그 는 ! 2개의 목록으로 구성됩니다concat, 추추 , , , , , , ,. operator.concat사용할 필요가 있습니다.
기능하고 있다고 생각되는 경우는, 다음과 같이 간단합니다.
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> reduce(operator.concat, list2d)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
시퀀스 타입에 대한 reduced가 표시되므로 태플을 제공하면 태플이 반환됩니다.다음 목록으로 시험해 보겠습니다.
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(operator.concat, list2d)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
아하, 목록을 돌려받았군
퍼포먼스는 어떻습니까?
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> %timeit list(itertools.chain.from_iterable(list2d))
1000000 loops, best of 3: 1.36 µs per loop
from_itable은 매우 빠릅니다!하지만 콘카트와 비교할 수 없습니다.
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> %timeit reduce(operator.concat, list2d)
1000000 loops, best of 3: 492 ns per loop
즉석에서 람다를 없앨 수 있어
reduce(list.__add__, map(list, [mi.image_set.all() for mi in list_of_menuitems]))
또는 이미 리스트 컴포넌트가 있기 때문에 맵을 삭제할 수도 있습니다.
reduce(list.__add__, [list(mi.image_set.all()) for mi in list_of_menuitems])
이것을 리스트의 합계로서 나타낼 수도 있습니다.
sum([list(mi.image_set.all()) for mi in list_of_menuitems], [])
리스트의 이해를 사용한 올바른 솔루션을 다음에 나타냅니다(질문은 거꾸로 되어 있습니다).
>>> join = lambda it: (y for x in it for y in x)
>>> list(join([[1,2],[3,4,5],[]]))
[1, 2, 3, 4, 5]
당신의 경우라면
[image for menuitem in list_of_menuitems for image in menuitem.image_set.all()]
'어울릴 수 없다'를 해도 됩니다.join라고 말하고
join(menuitem.image_set.all() for menuitem in list_of_menuitems)
어느 경우든, gotcha는 그 집 안에 있는for루프
이 버전은 제너레이터입니다.목록을 원하시면 수정하세요.
def list_or_tuple(l):
return isinstance(l,(list,tuple))
## predicate will select the container to be flattened
## write your own as required
## this one flattens every list/tuple
def flatten(seq,predicate=list_or_tuple):
## recursive generator
for i in seq:
if predicate(seq):
for j in flatten(i):
yield j
else:
yield i
조건을 만족시키는 술어를 평탄하게 하려면 , 술어를 추가할 수 있습니다.
비단뱀 요리책에서 따온 것
반복할 수 없는 요소 또는 깊이가 3 이상인 복잡한 목록을 평활해야 하는 경우 다음 기능을 사용할 수 있습니다.
def flat_list(list_to_flat):
if not isinstance(list_to_flat, list):
yield list_to_flat
else:
for item in list_to_flat:
yield from flat_list(item)
생성기 개체를 반환하며, 이 개체를 목록으로 변환할 수 있습니다.list()기능.주의해 주세요yield frompython3.3부터 구문을 사용할 수 있지만 대신 명시적 반복을 사용할 수 있습니다.
예:
>>> a = [1, [2, 3], [1, [2, 3, [1, [2, 3]]]]]
>>> print(list(flat_list(a)))
[1, 2, 3, 1, 2, 3, 1, 2, 3]
아래는 여러 레벨의 리스트에서 동작하는 버전입니다.collectons.Iterable:
import collections
def flatten(o, flatten_condition=lambda i: isinstance(i,
collections.Iterable) and not isinstance(i, str)):
result = []
for i in o:
if flatten_condition(i):
result.extend(flatten(i, flatten_condition))
else:
result.append(i)
return result
납작하게 해 본 적 있어요?matplotlib.cbook에서.평탄(seq, scalarp=)
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("list(flatten(l))")
3732 function calls (3303 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
429 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
429 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
429 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
727/298 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
429 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
858 0.001 0.000 0.001 0.000 {isinstance}
429 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("list(flatten(l))")
7461 function calls (6603 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
858 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
858 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
858 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
1453/595 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
858 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
1716 0.001 0.000 0.001 0.000 {isinstance}
858 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("list(flatten(l))")
11190 function calls (9903 primitive calls) in 0.010 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.010 0.010 <string>:1(<module>)
1287 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1287 0.003 0.000 0.004 0.000 cbook.py:484(is_string_like)
1287 0.002 0.000 0.009 0.000 cbook.py:565(is_scalar_or_string)
2179/892 0.001 0.000 0.010 0.000 cbook.py:605(flatten)
1287 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
2574 0.001 0.000 0.001 0.000 {isinstance}
1287 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("list(flatten(l))")
14919 function calls (13203 primitive calls) in 0.013 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.013 0.013 <string>:1(<module>)
1716 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1716 0.004 0.000 0.006 0.000 cbook.py:484(is_string_like)
1716 0.003 0.000 0.011 0.000 cbook.py:565(is_scalar_or_string)
2905/1189 0.002 0.000 0.013 0.000 cbook.py:605(flatten)
1716 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
3432 0.001 0.000 0.001 0.000 {isinstance}
1716 0.001 0.000 0.001 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler'
업데이트 다른 아이디어가 떠올랐습니다.
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("flattenlist(l)")
564 function calls (432 primitive calls) in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
133/1 0.000 0.000 0.000 0.000 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
429 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("flattenlist(l)")
1125 function calls (861 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
265/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
858 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("flattenlist(l)")
1686 function calls (1290 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
397/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
1287 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("flattenlist(l)")
2247 function calls (1719 primitive calls) in 0.002 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
529/1 0.001 0.000 0.002 0.002 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.002 0.002 <string>:1(<module>)
1716 0.001 0.000 0.001 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
run("flattenlist(l)")
22443 function calls (17163 primitive calls) in 0.016 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5281/1 0.011 0.000 0.016 0.016 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.016 0.016 <string>:1(<module>)
17160 0.005 0.000 0.005 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
따라서 재귀가 깊어질 때 얼마나 효과적인지 테스트하려면:얼마나 더 깊어?
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
new=[l]*33
run("flattenlist(new)")
740589 function calls (566316 primitive calls) in 0.418 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
174274/1 0.281 0.000 0.417 0.417 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.001 0.001 0.418 0.418 <string>:1(<module>)
566313 0.136 0.000 0.136 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*66
run("flattenlist(new)")
1481175 function calls (1132629 primitive calls) in 0.809 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
348547/1 0.542 0.000 0.807 0.807 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 0.809 0.809 <string>:1(<module>)
1132626 0.266 0.000 0.266 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*99
run("flattenlist(new)")
2221761 function calls (1698942 primitive calls) in 1.211 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
522820/1 0.815 0.000 1.208 1.208 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 1.211 1.211 <string>:1(<module>)
1698939 0.393 0.000 0.393 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*132
run("flattenlist(new)")
2962347 function calls (2265255 primitive calls) in 1.630 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
697093/1 1.091 0.000 1.627 1.627 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.003 0.003 1.630 1.630 <string>:1(<module>)
2265252 0.536 0.000 0.536 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*1320
run("flattenlist(new)")
29623443 function calls (22652523 primitive calls) in 16.103 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
6970921/1 10.842 0.000 16.069 16.069 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.034 0.034 16.103 16.103 <string>:1(<module>)
22652520 5.227 0.000 5.227 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
matploblib.cbook에서 "flaten"을 사용하는 것과 같이 수율 발생기와 빠른 결과를 원하지 않는 한, "flatenlist"는 matploblib보다 오래 사용할 것입니다.
이거 빠르네.
- 그리고 여기 암호가 있습니다.
:
typ=(list,tuple)
def flattenlist(d):
thelist = []
for x in d:
if not isinstance(x,typ):
thelist += [x]
else:
thelist += flattenlist(x)
return thelist
제 경험상 목록 목록을 정리하는 가장 효율적인 방법은 다음과 같습니다.
flat_list = []
map(flat_list.extend, list_of_list)
제안된 다른 방법과의 시간 비교:
list_of_list = [range(10)]*1000
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 119 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#1000 loops, best of 3: 210 µs per loop
%timeit flat_list=[i for sublist in list_of_list for i in sublist]
#1000 loops, best of 3: 525 µs per loop
%timeit flat_list=reduce(list.__add__,list_of_list)
#100 loops, best of 3: 18.1 ms per loop
이제 하위 목록을 길게 처리하면 효율성이 더 향상됩니다.
list_of_list = [range(1000)]*10
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 60.7 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#10000 loops, best of 3: 176 µs per loop
또한 이 메서드는 모든 반복 개체와 함께 작동합니다.
class SquaredRange(object):
def __init__(self, n):
self.range = range(n)
def __iter__(self):
for i in self.range:
yield i**2
list_of_list = [SquaredRange(5)]*3
flat_list = []
map(flat_list.extend, list_of_list)
print flat_list
#[0, 1, 4, 9, 16, 0, 1, 4, 9, 16, 0, 1, 4, 9, 16]
def is_iterable(item):
return isinstance(item, list) or isinstance(item, tuple)
def flatten(items):
for i in items:
if is_iterable(item):
for m in flatten(i):
yield m
else:
yield i
테스트:
print list(flatten2([1.0, 2, 'a', (4,), ((6,), (8,)), (((8,),(9,)), ((12,),(10)))]))
그럼 어떻게 되는 거죠?
from operator import add
reduce(add, map(lambda x: list(x.image_set.all()), [mi for mi in list_of_menuitems]))
그러나 Guido는 가독성을 떨어뜨리기 때문에 한 줄의 코드에서 너무 많은 작업을 수행하지 말 것을 권장합니다.원하는 것을 한 줄에서 여러 줄에서 수행함으로써 성능 향상을 최소화할 수 있습니다.
pylab은 평탄한 상태를 제공한다: numpy 평탄한 상태로의 링크
빌트인의 심플한 원라이너를 원하신다면 다음을 이용하실 수 있습니다.
a = [[1, 2, 3], [4, 5, 6]
b = [i[x] for i in a for x in range(len(i))]
print b
돌아온다
[1, 2, 3, 4, 5, 6]
리스트내의 각 항목이 문자열인 경우(또, 이러한 문자열내의 문자열이 「」이 아닌 「」를 사용하고 있는 경우), 정규 표현( )을 사용할 수 있습니다.re모듈)
>>> flattener = re.compile("\'.*?\'")
>>> flattener
<_sre.SRE_Pattern object at 0x10d439ca8>
>>> stred = str(in_list)
>>> outed = flattener.findall(stred)
위의 코드는 in_list를 문자열로 변환하고 regex를 사용하여 따옴표 내의 모든 하위 문자열(목록의 각 항목)을 찾아 목록으로 내뱉습니다.
간단한 대안은 numpy's concatenate를 사용하는 것이지만 내용을 플로트로 변환합니다.
import numpy as np
print np.concatenate([[1,2],[3],[5,89],[],[6]])
# array([ 1., 2., 3., 5., 89., 6.])
print list(np.concatenate([[1,2],[3],[5,89],[],[6]]))
# [ 1., 2., 3., 5., 89., 6.]
Python 2 또는 3에서 이를 달성하는 가장 쉬운 방법은 다음을 사용하여 morph 라이브러리를 사용하는 것입니다.pip install morph.
코드는 다음과 같습니다.
import morph
list = [[1,2],[3],[5,89],[],[6]]
flattened_list = morph.flatten(list) # returns [1, 2, 3, 5, 89, 6]
[*innerlist for innerlist in outer_list]
언급URL : https://stackoverflow.com/questions/406121/flattening-a-shallow-list-in-python
'source' 카테고리의 다른 글
| MyISAM 레코드가 3억 5천만 개 이상인 25GB의 대용량 테이블을 업데이트하려면 어떻게 해야 합니까? (0) | 2022.11.19 |
|---|---|
| 이름이 같은 두 클래스를 가져오는 중입니다.어떻게 대처해야 할까? (0) | 2022.11.19 |
| AWS RDS - 'the_db.*'에서 'the_user'@%'에 대한 GRANT ALL Privileges ON을 사용할 때 관리 사용자에 대한 액세스가 거부되었습니다. (0) | 2022.11.19 |
| Python에서 주 번호를 얻는 방법은 무엇입니까? (0) | 2022.11.19 |
| Python: None을 빈 문자열로 변환하는 가장 관용적인 방법? (0) | 2022.11.19 |